mirror of
https://github.com/eledio-devices/thirdparty-littlefs.git
synced 2025-10-31 00:32:38 +01:00
Updated SPEC.md and DESIGN.md based on recent changes
- Added math behind CTZ limits - Added documentation over atomic moves
This commit is contained in:
250
DESIGN.md
250
DESIGN.md
@@ -200,7 +200,7 @@ Now we could just leave files here, copying the entire file on write
|
||||
provides the synchronization without the duplicated memory requirements
|
||||
of the metadata blocks. However, we can do a bit better.
|
||||
|
||||
## CTZ linked-lists
|
||||
## CTZ skip-lists
|
||||
|
||||
There are many different data structures for representing the actual
|
||||
files in filesystems. Of these, the littlefs uses a rather unique [COW](https://upload.wikimedia.org/wikipedia/commons/0/0c/Cow_female_black_white.jpg)
|
||||
@@ -246,19 +246,19 @@ runtime to just _read_ a file? That's awful. Keep in mind reading files are
|
||||
usually the most common filesystem operation.
|
||||
|
||||
To avoid this problem, the littlefs uses a multilayered linked-list. For
|
||||
every block that is divisible by a power of two, the block contains an
|
||||
additional pointer that points back by that power of two. Another way of
|
||||
thinking about this design is that there are actually many linked-lists
|
||||
threaded together, with each linked-lists skipping an increasing number
|
||||
of blocks. If you're familiar with data-structures, you may have also
|
||||
recognized that this is a deterministic skip-list.
|
||||
every nth block where n is divisible by 2^x, the block contains a pointer
|
||||
to block n-2^x. So each block contains anywhere from 1 to log2(n) pointers
|
||||
that skip to various sections of the preceding list. If you're familiar with
|
||||
data-structures, you may have recognized that this is a type of deterministic
|
||||
skip-list.
|
||||
|
||||
To find the power of two factors efficiently, we can use the instruction
|
||||
[count trailing zeros (CTZ)](https://en.wikipedia.org/wiki/Count_trailing_zeros),
|
||||
which is where this linked-list's name comes from.
|
||||
The name comes from the use of the
|
||||
[count trailing zeros (CTZ)](https://en.wikipedia.org/wiki/Count_trailing_zeros)
|
||||
instruction, which allows us to calculate the power-of-two factors efficiently.
|
||||
For a given block n, the block contains ctz(n)+1 pointers.
|
||||
|
||||
```
|
||||
Exhibit C: A backwards CTZ linked-list
|
||||
Exhibit C: A backwards CTZ skip-list
|
||||
.--------. .--------. .--------. .--------. .--------. .--------.
|
||||
| data 0 |<-| data 1 |<-| data 2 |<-| data 3 |<-| data 4 |<-| data 5 |
|
||||
| |<-| |--| |<-| |--| | | |
|
||||
@@ -266,6 +266,9 @@ Exhibit C: A backwards CTZ linked-list
|
||||
'--------' '--------' '--------' '--------' '--------' '--------'
|
||||
```
|
||||
|
||||
The additional pointers allow us to navigate the data-structure on disk
|
||||
much more efficiently than in a single linked-list.
|
||||
|
||||
Taking exhibit C for example, here is the path from data block 5 to data
|
||||
block 1. You can see how data block 3 was completely skipped:
|
||||
```
|
||||
@@ -285,15 +288,57 @@ The path to data block 0 is even more quick, requiring only two jumps:
|
||||
'--------' '--------' '--------' '--------' '--------' '--------'
|
||||
```
|
||||
|
||||
The CTZ linked-list has quite a few interesting properties. All of the pointers
|
||||
in the block can be found by just knowing the index in the list of the current
|
||||
block, and, with a bit of math, the amortized overhead for the linked-list is
|
||||
only two pointers per block. Most importantly, the CTZ linked-list has a
|
||||
worst case lookup runtime of O(logn), which brings the runtime of reading a
|
||||
file down to O(n logn). Given that the constant runtime is divided by the
|
||||
amount of data we can store in a block, this is pretty reasonable.
|
||||
We can find the runtime complexity by looking at the path to any block from
|
||||
the block containing the most pointers. Every step along the path divides
|
||||
the search space for the block in half. This gives us a runtime of O(log n).
|
||||
To get to the block with the most pointers, we can perform the same steps
|
||||
backwards, which keeps the asymptotic runtime at O(log n). The interesting
|
||||
part about this data structure is that this optimal path occurs naturally
|
||||
if we greedily choose the pointer that covers the most distance without passing
|
||||
our target block.
|
||||
|
||||
Here is what it might look like to update a file stored with a CTZ linked-list:
|
||||
So now we have a representation of files that can be appended trivially with
|
||||
a runtime of O(1), and can be read with a worst case runtime of O(n logn).
|
||||
Given that the the runtime is also divided by the amount of data we can store
|
||||
in a block, this is pretty reasonable.
|
||||
|
||||
Unfortunately, the CTZ skip-list comes with a few questions that aren't
|
||||
straightforward to answer. What is the overhead? How do we handle more
|
||||
pointers than we can store in a block?
|
||||
|
||||
One way to find the overhead per block is to look at the data structure as
|
||||
multiple layers of linked-lists. Each linked-list skips twice as many blocks
|
||||
as the previous linked-list. Or another way of looking at it is that each
|
||||
linked-list uses half as much storage per block as the previous linked-list.
|
||||
As we approach infinity, the number of pointers per block forms a geometric
|
||||
series. Solving this geometric series gives us an average of only 2 pointers
|
||||
per block.
|
||||
|
||||
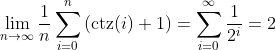
|
||||
|
||||
Finding the maximum number of pointers in a block is a bit more complicated,
|
||||
but since our file size is limited by the integer width we use to store the
|
||||
size, we can solve for it. Setting the overhead of the maximum pointers equal
|
||||
to the block size we get the following equation. Note that a smaller block size
|
||||
results in more pointers, and a larger word width results in larger pointers.
|
||||
|
||||
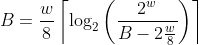
|
||||
|
||||
where:
|
||||
B = block size in bytes
|
||||
w = word width in bits
|
||||
|
||||
Solving the equation for B gives us the minimum block size for various word
|
||||
widths:
|
||||
32 bit CTZ skip-list = minimum block size of 104 bytes
|
||||
64 bit CTZ skip-list = minimum block size of 448 bytes
|
||||
|
||||
Since littlefs uses a 32 bit word size, we are limited to a minimum block
|
||||
size of 104 bytes. This is a perfectly reasonable minimum block size, with most
|
||||
block sizes starting around 512 bytes. So we can avoid the additional logic
|
||||
needed to avoid overflowing our block's capacity in the CTZ skip-list.
|
||||
|
||||
Here is what it might look like to update a file stored with a CTZ skip-list:
|
||||
```
|
||||
block 1 block 2
|
||||
.---------.---------.
|
||||
@@ -367,7 +412,7 @@ v
|
||||
## Block allocation
|
||||
|
||||
So those two ideas provide the grounds for the filesystem. The metadata pairs
|
||||
give us directories, and the CTZ linked-lists give us files. But this leaves
|
||||
give us directories, and the CTZ skip-lists give us files. But this leaves
|
||||
one big [elephant](https://upload.wikimedia.org/wikipedia/commons/3/37/African_Bush_Elephant.jpg)
|
||||
of a question. How do we get those blocks in the first place?
|
||||
|
||||
@@ -653,9 +698,17 @@ deorphan step that simply iterates through every directory in the linked-list
|
||||
and checks it against every directory entry in the filesystem to see if it
|
||||
has a parent. The deorphan step occurs on the first block allocation after
|
||||
boot, so orphans should never cause the littlefs to run out of storage
|
||||
prematurely.
|
||||
prematurely. Note that the deorphan step never needs to run in a readonly
|
||||
filesystem.
|
||||
|
||||
And for my final trick, moving a directory:
|
||||
## The move problem
|
||||
|
||||
Now we have a real problem. How do we move things between directories while
|
||||
remaining power resilient? Even looking at the problem from a high level,
|
||||
it seems impossible. We can update directory blocks atomically, but atomically
|
||||
updating two independent directory blocks is not an atomic operation.
|
||||
|
||||
Here's the steps the filesystem may go through to move a directory:
|
||||
```
|
||||
.--------.
|
||||
|root dir|-.
|
||||
@@ -716,18 +769,135 @@ v
|
||||
'--------'
|
||||
```
|
||||
|
||||
Note that once again we don't care about the ordering of directories in the
|
||||
linked-list, so we can simply leave directories in their old positions. This
|
||||
does make the diagrams a bit hard to draw, but the littlefs doesn't really
|
||||
care.
|
||||
We can leave any orphans up to the deorphan step to collect, but that doesn't
|
||||
help the case where dir A has both dir B and the root dir as parents if we
|
||||
lose power inconveniently.
|
||||
|
||||
It's also worth noting that once again we have an operation that isn't actually
|
||||
atomic. After we add directory A to directory B, we could lose power, leaving
|
||||
directory A as a part of both the root directory and directory B. However,
|
||||
there isn't anything inherent to the littlefs that prevents a directory from
|
||||
having multiple parents, so in this case, we just allow that to happen. Extra
|
||||
care is taken to only remove a directory from the linked-list if there are
|
||||
no parents left in the filesystem.
|
||||
Initially, you might think this is fine. Dir A _might_ end up with two parents,
|
||||
but the filesystem will still work as intended. But then this raises the
|
||||
question of what do we do when the dir A wears out? For other directory blocks
|
||||
we can update the parent pointer, but for a dir with two parents we would need
|
||||
work out how to update both parents. And the check for multiple parents would
|
||||
need to be carried out for every directory, even if the directory has never
|
||||
been moved.
|
||||
|
||||
It also presents a bad user-experience, since the condition of ending up with
|
||||
two parents is rare, it's unlikely user-level code will be prepared. Just think
|
||||
about how a user would recover from a multi-parented directory. They can't just
|
||||
remove one directory, since remove would report the directory as "not empty".
|
||||
|
||||
Other atomic filesystems simple COW the entire directory tree. But this
|
||||
introduces a significant bit of complexity, which leads to code size, along
|
||||
with a surprisingly expensive runtime cost during what most users assume is
|
||||
a single pointer update.
|
||||
|
||||
Another option is to update the directory block we're moving from to point
|
||||
to the destination with a sort of predicate that we have moved if the
|
||||
destination exists. Unfortunately, the omnipresent concern of wear could
|
||||
cause any of these directory entries to change blocks, and changing the
|
||||
entry size before a move introduces complications if it spills out of
|
||||
the current directory block.
|
||||
|
||||
So how do we go about moving a directory atomically?
|
||||
|
||||
We rely on the improbableness of power loss.
|
||||
|
||||
Power loss during a move is certainly possible, but it's actually relatively
|
||||
rare. Unless a device is writing to a filesystem constantly, it's unlikely that
|
||||
a power loss will occur during filesystem activity. We still need to handle
|
||||
the condition, but runtime during a power loss takes a back seat to the runtime
|
||||
during normal operations.
|
||||
|
||||
So what littlefs does is unelegantly simple. When littlefs moves a file, it
|
||||
marks the file as "moving". This is stored as a single bit in the directory
|
||||
entry and doesn't take up much space. Then littlefs moves the directory,
|
||||
finishing with the complete remove of the "moving" directory entry.
|
||||
|
||||
```
|
||||
.--------.
|
||||
|root dir|-.
|
||||
| pair 0 | |
|
||||
.--------| |-'
|
||||
| '--------'
|
||||
| .-' '-.
|
||||
| v v
|
||||
| .--------. .--------.
|
||||
'->| dir A |->| dir B |
|
||||
| pair 0 | | pair 0 |
|
||||
| | | |
|
||||
'--------' '--------'
|
||||
|
||||
| update root directory to mark directory A as moving
|
||||
v
|
||||
|
||||
.----------.
|
||||
|root dir |-.
|
||||
| pair 0 | |
|
||||
.-------| moving A!|-'
|
||||
| '----------'
|
||||
| .-' '-.
|
||||
| v v
|
||||
| .--------. .--------.
|
||||
'->| dir A |->| dir B |
|
||||
| pair 0 | | pair 0 |
|
||||
| | | |
|
||||
'--------' '--------'
|
||||
|
||||
| update directory B to point to directory A
|
||||
v
|
||||
|
||||
.----------.
|
||||
|root dir |-.
|
||||
| pair 0 | |
|
||||
.-------| moving A!|-'
|
||||
| '----------'
|
||||
| .-----' '-.
|
||||
| | v
|
||||
| | .--------.
|
||||
| | .->| dir B |
|
||||
| | | | pair 0 |
|
||||
| | | | |
|
||||
| | | '--------'
|
||||
| | .-------'
|
||||
| v v |
|
||||
| .--------. |
|
||||
'->| dir A |-'
|
||||
| pair 0 |
|
||||
| |
|
||||
'--------'
|
||||
|
||||
| update root to no longer contain directory A
|
||||
v
|
||||
.--------.
|
||||
|root dir|-.
|
||||
| pair 0 | |
|
||||
.----| |-'
|
||||
| '--------'
|
||||
| |
|
||||
| v
|
||||
| .--------.
|
||||
| .->| dir B |
|
||||
| | | pair 0 |
|
||||
| '--| |-.
|
||||
| '--------' |
|
||||
| | |
|
||||
| v |
|
||||
| .--------. |
|
||||
'--->| dir A |-'
|
||||
| pair 0 |
|
||||
| |
|
||||
'--------'
|
||||
```
|
||||
|
||||
Now, if we run into a directory entry that has been marked as "moved", one
|
||||
of two things is possible. Either the directory entry exists elsewhere in the
|
||||
filesystem, or it doesn't. This is a O(n) operation, but only occurs in the
|
||||
unlikely case we lost power during a move.
|
||||
|
||||
And we can easily fix the "moved" directory entry. Since we're already scanning
|
||||
the filesystem during the deorphan step, we can also check for moved entries.
|
||||
If we find one, we either remove the "moved" marking or remove the whole entry
|
||||
if it exists elsewhere in the filesystem.
|
||||
|
||||
## Wear awareness
|
||||
|
||||
@@ -955,18 +1125,18 @@ So, to summarize:
|
||||
|
||||
1. The littlefs is composed of directory blocks
|
||||
2. Each directory is a linked-list of metadata pairs
|
||||
3. These metadata pairs can be updated atomically by alternative which
|
||||
3. These metadata pairs can be updated atomically by alternating which
|
||||
metadata block is active
|
||||
4. Directory blocks contain either references to other directories or files
|
||||
5. Files are represented by copy-on-write CTZ linked-lists
|
||||
6. The CTZ linked-lists support appending in O(1) and reading in O(n logn)
|
||||
7. Blocks are allocated by scanning the filesystem for used blocks in a
|
||||
5. Files are represented by copy-on-write CTZ skip-lists which support O(1)
|
||||
append and O(n logn) reading
|
||||
6. Blocks are allocated by scanning the filesystem for used blocks in a
|
||||
fixed-size lookahead region is that stored in a bit-vector
|
||||
8. To facilitate scanning the filesystem, all directories are part of a
|
||||
7. To facilitate scanning the filesystem, all directories are part of a
|
||||
linked-list that is threaded through the entire filesystem
|
||||
9. If a block develops an error, the littlefs allocates a new block, and
|
||||
8. If a block develops an error, the littlefs allocates a new block, and
|
||||
moves the data and references of the old block to the new.
|
||||
10. Any case where an atomic operation is not possible, it is taken care of
|
||||
9. Any case where an atomic operation is not possible, mistakes are resolved
|
||||
by a deorphan step that occurs on the first allocation after boot
|
||||
|
||||
That's the little filesystem. Thanks for reading!
|
||||
|
||||
Reference in New Issue
Block a user